
Data beveiligen en controleren? Gebruik gevoeligheidslabels!
Via allerlei kanalen delen we op de werkvloer de hele dag door verschillende bestanden met elkaar. Een e-mailtje met een CV van een sollicitant, een ondertekende offerte van een klant of een berichtje met foto in de chat. Vaak zijn we ons helemaal niet bewust van de hoeveelheid van én welke data precies gedeeld wordt, en op welke manier dat gebeurt. Welke data is er binnen je organisatie? Waar staat deze informatie en wie heeft er toegang toe? En misschien wel belangrijker: beschermen we deze data tegen toegang door onbevoegden én hoe voorkomen we het uitlekken ervan? Om volledige controle te hebben over deze informatie dienen mens, organisatie en techniek op elkaar afgestemd te zijn. Best een opgave. Hoe zorg je dat je in control bent over al deze data?
Gegevens classificeren met Microsoft Information Protection
Om grip te krijgen op dit vraagstuk is inzet van zogenoemde gevoeligheidslabels een belangrijke stap. Door middel van deze labels geef je inzicht in gevoelige data en krijg je controle over de beheersing ervan. Het wordt inzichtelijk waar data zich bevindt. Vervolgens wordt deze data beveiligd en het risico op gegevensverlies gereduceerd.
Deze oplossing met gevoeligheidslabels is onderdeel van het Microsoft 365 Compliance onderdeel, genaamd Microsoft Information Protection. Dit maakt het mogelijk gegevens te classificeren op veel locaties binnen de digitale werkplek, waaronder postvakken gehost binnen Exchange Online, teams aangemaakt binnen Microsoft Teams, communities in Yammer, persoonlijke opslaglocaties binnen OneDrive, sites op SharePoint, noem maar op. Met Microsoft Information Protection kunnen berichten door medewerkers handmatig van een label worden voorzien, of het systeem kan op basis van bepaalde kenmerken automatisch een label toekennen.
Gegevensclassificatie in de praktijk
Om data te voorzien van het juiste label, wordt gebruik gemaakt van een gegevensclassificatiemodel. Een veelgebruikte variant is bijvoorbeeld het 5-laagse model, zoals hieronder afgebeeld. Dit model maakt het mogelijk zowel niet-zakelijke als zakelijke data te onderscheiden. Zakelijke gegevens zijn vervolgens onderverdeeld in algemene, confidentiële en hoog confidentiële informatie.

Maar hoe werken die gevoeligheidslabels na het kiezen van een model nou in de praktijk? Nadat een medewerker een label heeft gekozen voor een e-mailbericht of document, wordt het bijbehorende beleid afgedwongen. Zo kan een document gemarkeerd als ‘hoog confidentieel’ automatisch van visuele markeringen voorzien worden, zoals weergegeven in het voorbeeld hieronder. Voor e-mailberichten voorzien van een classificatie kan bijvoorbeeld afgedwongen worden dat deze versleuteld worden verzonden en het doorsturen ervan wordt geweigerd.
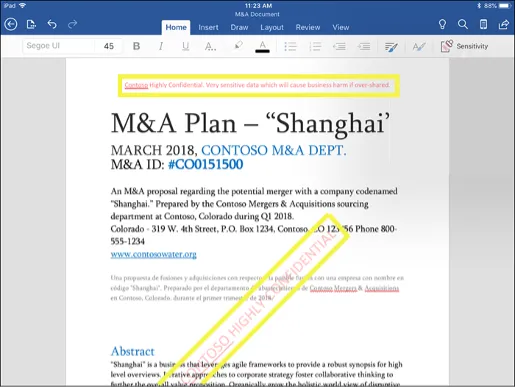
Een model dat past bij jouw organisatie
Niet in elke organisatie past hetzelfde gegevensclassificatiemodel, labels of bijbehorende beleid. Daarom is maatwerk belangrijk. Hoe wij dat aanpakken? Samen gaan we op zoek naar het model dat het best bij jouw organisatie past. Aan de start van zo’n traject onderzoeken we uitgebreid wat aansluit bij jouw medewerkers en jouw beleid. Aan de hand van best-practices bepalen we in hoeverre een standaard gegevensclassificatiemodel geschikt zou zijn, of dat specifiekere labels nodig zijn.
Dan gaat de pilotfase van start, waarin we de gevoeligheidslabels met een kleine groep medewerkers in de organisatie testen en evalueren. Deelnemers uit de pilot geven in hun e-mail en documenten het gevoeligheidsniveau van de content aan, waarop het ingerichte systeem automatisch het bijbehorende beleid afdwingt.
Resultaten uit de pilotfase worden uitgebreid geëvalueerd en het systeem wordt hierop aangepast. Is iedereen tevreden en is het model werkbaar? Dan worden de handmatige gevoeligheidslabels beschikbaar voor de hele organisatie. Uiteraard worden alle medewerkers tijdens dit verandertraject nauwkeurig door ons begeleid.
Verderop in het proces zetten we naast handmatige classificatie door de medewerker ook automatische classificatie in. De eerder vastgestelde gevoeligheidslabels worden dan ingezet om informatie die voldoet aan kenmerken automatisch te labelen.
Inzicht met data classificatie dashboard
Na het inrichten van deze nieuwe manier van werken, komt steeds meer informatie over deze data beschikbaar. Hoe meer data, hoe meer inzicht. Op het data classificatie dashboard wordt stapsgewijs inzichtelijk hoeveel bestanden zijn gelabeld en hoe vaak bepaalde labels zijn toegepast en op welke locatie. Ook is het mogelijk om inzicht te krijgen in welke informatie handmatig en welke automatisch geclassificeerd is. Hieronder vind je een impressie van hoe zo’n dashboard eruit ziet.
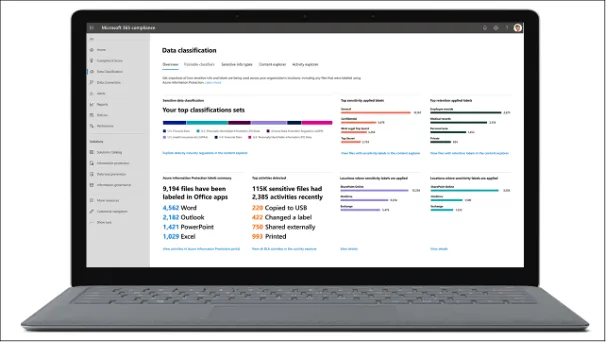
Met gevoeligheidslabels, een gegevensclassificatiemodel en bijbehorend dashboard word jij weer in controle over de data in jouw organisatie. Lijkt de classificering op basis van gevoeligheidslabels je iets voor jouw bedrijf? Neem dan contact met ons op!
Meer kennis

De toegevoegde waarde van Workplace Analytics voor mijn medewerkers
